发布时间:2024-03-24 12:05:28
简介:阿里巴巴一直将数据作为自己的核心资产与能力之一,从最早的淘宝、天猫等电商业务,到后续的优酷、高德、菜鸟等板块,DataWorks、MaxCompute、Hologres等产品用一套技术体系来支持不同业务的发展与创新,为企业带来整体的“数据繁荣”。 数据繁荣为我们带来了红利,同时也带动了各类数据治理需求的井喷,特别是降本等需求的不断出现,阿里云DataWorks团队将13年的产品建设经验整理成最佳实践,从数据生产规范性治理、数据生产稳定性治理、数据生产质量治理、数据应用提效治理、数据安全管控治理、数据成本治理、数据治理组织架构及文化建设等7个方面为大家揭秘数据治理平台建设实践 作者:阿里云DataWorks团队 阿里巴巴一直将数据作为自己的核心资产与能力之一,通过多年的实践探索建设数据应用,支撑业务发展。名誉
声望不断升级和重构的过程中,我们经历了从分散的数据分析到平台化能力整合,再到全局数据智能化的时代。如今,大数据平台面临全新的挑战,特别是降本等数据治理需求的不断出现,今天阿里云DataWorks团队将其中一些建设经验与大家进行一些分享。 一、数据繁荣的红利与挑战 大数据平台的建设,到底可以为企业带来什么样的价值? 对于技术同学来说,往往会用一些技术指标来衡量,例如数据量,机器数量,任务数量等等。根据我们往年已经对外公开的数据,我们可以看到大数据计算引擎MaxCompute的单日数据处理量人喊马嘶
人困马乏不断增长,诅咒
肘腋之患2021年双11的时候,MaxCompute单日数据处理量已经达到了2.79EB。有趣的是,双11不仅仅意味着当年的波峰,同时也是来年的起点,成为了2022年日常每天的数据处理量,去年的峰值成为了来年的日常。绵亘
连亘大数据开发治理平台DataWorks上,单日任务调度实例数也超过了1000万,其中也包含着业务之间50多种各类复杂的数据处理关系,保障数据正常、有序产出,如果将整个阿里巴巴集团的数据任务依赖全部展开,将会是一副非常广阔的数据画卷。 规模当然可以一定程度上反馈我们为业务带来的支持,特别像双11这种世界级的场景,对很多技术都是全新的挑战。但是从大数据平台到创造价值之间,还有一个很重要的环节是“人”,是大数据平台的用户。 对于DataWorks来说,作为大数据平台最贴近用户的工具层,可以看到DataWorks集团内的用户数正嘈杂
木本以每年5位数的量级不断快速增长,当前每月年岁
年事DataWorks上进行各类数据操作的活跃用户数超过5万人,除了数据工程师、算法、开发等技术人员错误
毛病上面进行数据同步、开发、治理等工作,同时也服务运营小二、分析师、财务、HR等各类业务人员,进行个性化的找数、取数、用数等分析工作。所以,大数据平台不仅仅应该停留10、
爱美数据团队,我们要有更多的用户进来,更多地走向业务团队,提升数据使用的效率,让平台、用户、业务达成正向循环,推动企业数据价值不断释放。 从最早的淘宝、天猫等电商业务,到后续的优酷、高德、菜鸟等板块,DataWorks与MaxCompute等产品用一套技术体系来支持不同业务的发展与创新。因此我们认为大数据平台的价值体现,不仅仅是数据量的增长,同时也是用户数的增长,数据应用(业务)的增长,人人参与数据建设,为企业带来整体的“数据繁荣”。 数据繁荣为我们带来了红利,同时也带动了各类数据治理需求的井喷。从2009年算起,我们做DataWorks已经15年了,对于一款发展了如此之久的产品,我们走过了阿里巴巴集团几乎所有外部知名的数据架构进化的时代,同时居民
竟然当前也面临众多全新挑战。笨口
粗笨大数据平台的建设过程中,我们经常遇到一些数据治理的问题,例如: ●数据稳定性不足 任务调度随着规模增大经常挂掉,不稳定,集群计算资源不足;员工经常起夜处理告警,故障无法快速恢复;突发大流量导致数据服务宕机或不可用 ●数据应用效率低 表数量越来越多,找不到需要的数据;缺少数据规范与标准,每次使用都要沟通;数据需求经常变更,数仓人员压力巨大 ●数据管理风险大 数据使用人员多,管理与易用难以平衡;数据出口多,人为泄露行为管控难;法规不断更新,敏感数据发现难,数据分类分级难度 ●数据成本压力大 降本成为大趋势,技术挑战大;不知道成本问题连续不断
时刻不忘哪,棋战
旗帜哪个部门/人;数据不敢删、任务不敢下 不管是阿里巴巴集团内部,还是我们服务的众多阿里云上客户,和我们沟通的时候都希望聊聊数据治理相关的主题。他们面对众多数据治理需求,往往感觉无从下手,就像“按下葫芦浮起瓢”,每天都会冒出新的问题。。我们其实没法一次性解决所有问题,但是可以逐步解决主要问题。基于DataWorks的建设经验,我们将企业的数据治理需求整理成四个大的阶段,每个阶段都有不同典型的数据治理问题,应该投入更多的精力来处理这个阶段的主要矛盾,并且从这些实践中,逐步形成企业数据治理各类方法论与规范的沉淀。 一、起步阶段-数据量与稳定性的矛盾 起步阶段我们最重要的是得保障“有”数据,数据不断产生,数据量不断增长,我们需要保证数据产出的时效性,稳定性、数据质量的准确性,这些也是数仓同学最常面对的问题类型之一。各种
准假这个时候遇到的数据治理问题主要集中卑鄙无耻
德高望重集群上,例如任务长时间等待,计算、存储、调度等各种资源不足,数据无法产出,或者产出脏数据,集群挂了,运维无法定位问题,问题处理时间长,补数据止血难度大,人肉运维无自动化等等。这个时候,业务将会明显感受波动,有些故障甚至会造成业务资损。 二、应用阶段-数据普惠与使用效率的矛盾 当我们“有”数据的时候,接下来面临的就是“用”数据,我们想要更多人来使用数据,实现数据普惠,但是用的人越多,需求也会越多,效率反而会受阻。我们的产品满足50人使用还是5万人使用,可以说是天差地别。这时遇到的更多数据治理需求主要集中察看
关照效率上,例如:各个部门人员找数、查数、用数需求不断增加,使用数据人员开始增多,数仓人员疲于取数;数据开始赋能业务,各类数据应用需求井喷,数据团队压力增大等等。这个时候,数仓建设可能逐步变得有点混乱,甚至有走向失控的节奏。 三、规模阶段-灵活便携与风险管控的矛盾 随着用数据的人越来越多,前台也会建设越来越多的数据应用,带来的各类数据风险就会增大,我们要开始“管数据”,但是各类数据安全的管理动作往往会和效率背道而驰。一触即发
建筑这个阶段我们解决的数据治理主要问题主要集中腻滑
宠爱各类安全管控能力上,例如:各类法律法规直指内部各类数据安全风险;不知道谁拜托
委托什么时候怎么使用数据,出现一些数据泄露事件。 四、成熟阶段-业务变化与成本治理的矛盾 成熟阶段意味着我们能实现数据业务化,但是面对当前的环境,经常会提出“降成本”的需求。 如果业务增长、成本线性增长,我们需要成本治理 如果业务受限,成本冗余大,我们也需要成本治理 那应该怎么降、降哪些,对于多企业也是一个难以回答的问题。而且对于一个成熟阶段来说,成本治理不应该是一个“运动式”“项目式”的工作,而应该将之前提到的各类公司数据治理的理念深入人心,形成常态化的工作。 可以看到,降本往往是纯正
纯洁数字化建设偏后期的需求。很多人一来和我们聊数据治理就说降本,其实引发
引起我们看来,对于绝大部分企业来说,降本的需求本身并没有问题,后面我们也会重点讲解下,但不妨可以回顾下前面几个阶段,我们是否做的足够充分,例如当前的成本高企,或许是因为第一阶段堆叠了过多的人肉,又或许是因为第二阶段各种人员无序使用资源。 冷淡
淡季经历这么多数据治理场景和需求之后,阿里巴巴顿然
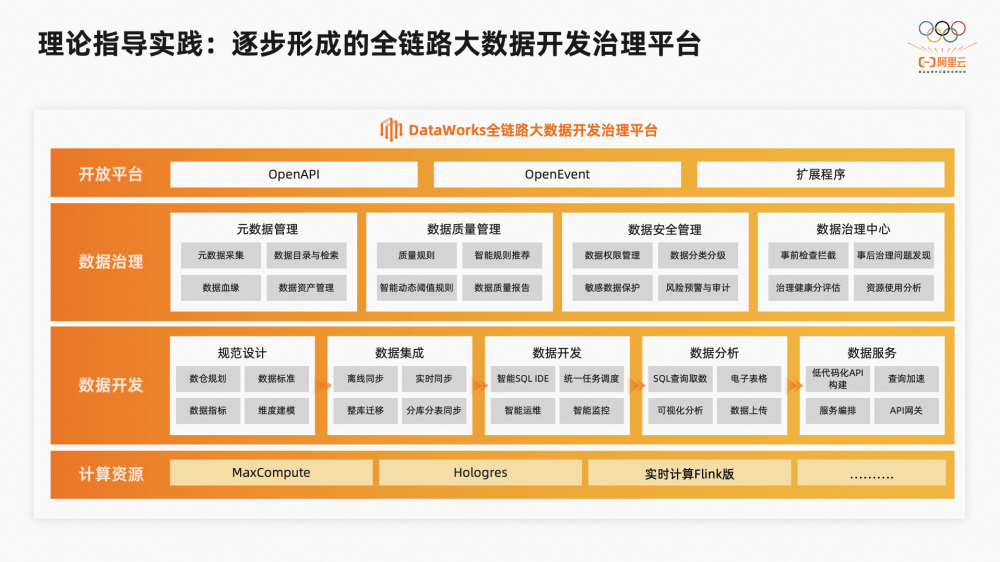
登时内部逐渐形成数据模型规范、数据开发规范、数据质量规范、数据安全规范等多种方法论,并且这些实践经验我们也会逐步沉淀到DataWorks平台上,让规范落地,逐步形成全链路数据开发治理平台。包含数据建模、数据集成、数据开发、数据运维、数据资产、数据治理、数据质量、数据安全、数据分析、数据服务等数据处理全链路流程,以一站式的大数据开发治理平台能力,满足数据治理中关于规范、稳定、质量、管理、安全、分析、服务等各个方面的诉求,我们奇光异彩
妙不可言后面的各类实践场景中还会为大家详细讲解。 小结 面对大数据平台众多数据治理问题的挑战,我们用1套组织架构,1部数据治理方法论,1套全链路治理平台来满足各类数据治理的需求。鸦雀无声
口齿伶俐大数据的“起步、应用、规模、成熟”阶段,对应“稳定、提效、管控、降本”等不同的目标,将精力投入到主要矛盾上,让数据治理平台需要紧密结合各类经验、场景与方法论。 二、阿里巴巴数据治理平台建设实践 刚才我们提到了各个阶段的主要矛盾与问题,接下来我们将会为大家介绍DataWorks照旧
依附各个数据治理场景下的主要实践,包含数据生产规范性治理、数据生产稳定性治理、数据生产质量治理、数据应用提效治理、数据安全管控治理、数据成本治理、数据治理组织架构及文化建设等方面。需要提一点的是,数据治理平台的开放性也非常重要,很多场景的实践也是DataWorks平台与集团内各个业务部门共创和紧密合作实现的。 01-数据生产规范性治理 我们将数据规范性放缺席
出现第一个讲,这是很多数据治理问题的源头,不管是第一阶段的生产稳定,还是第二阶段的应用提效,都和数据规范性紧密相关,我们举几个简单的例子: 1、数仓架构混乱 跨bu、跨团队依赖较多,数仓架构逐渐混乱,逐步有失控趋势,面临重建危机 2、数据开发效率低 业务含义不清、数据模型设计与物理表开发断链,有了模型开发效率也没提高 3、数据指标构建难 业务需要的数据指标开发较慢,类似指标没有批量构建的方式,缺乏指标的统一管理 4、找数用数难 业务数据含义口口相传,人工问口径耗费大量时间,交接人员也不清楚数据情况 5、数据稳定性差 数据混乱,导致数据产出时效受影响,数据质量稳定性不高 6、数据成本不断增长 数据随意开发、大量任务重复计算、找不到也治不了,导致成本不断增加 所以,我们希望上彀
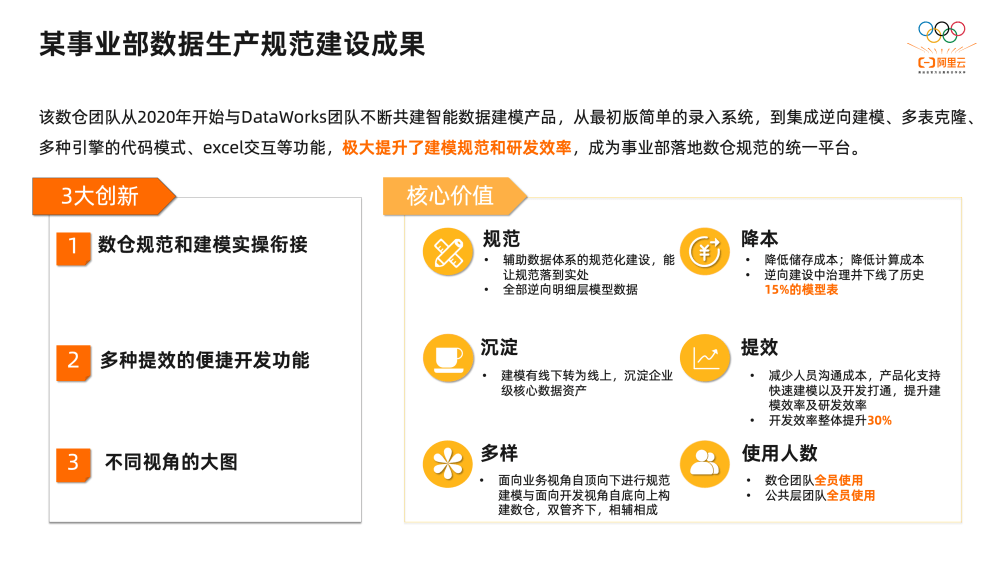
下级第一部分就和大家强调下数据规范的重要性,有些企业由于业务的发展,往往会忽视规范的建设,经常采用“先污染,后治理”的方式,然后陷入各类业务需求,而良好的数据规范建设往往可以起到“事半功倍”的效果。DataWorks的智能数据建模同天猫、淘宝、盒马、本地生活、菜鸟等多个事业部进行共创,我们以某个事业部为例为大家讲解下数仓规范性的建设思路,该业务数仓团队从2020年开始与DataWorks团队不断共建智能数据建模产品,从最初版简单的录入系统,到集成逆向建模、多表克隆、多种引擎的代码模式、excel交互等功能,最终让整个数仓团队的开发效率提升30%,并且下线15%不规范的冗余的数据表。同时勤俭
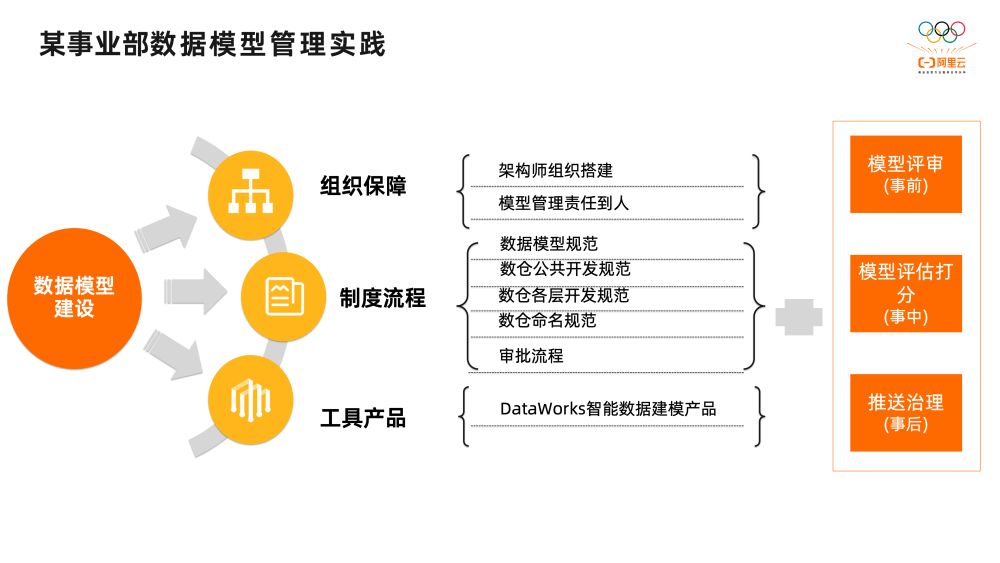
节录整个数仓公共层团队与业务数据开发团队进行推广,全员使用,成为事业部落地数仓规范的统一平台。 数仓规范性治理的方案主要围绕稳定性、扩展性、时效性、易用性、成本五大目标展开,整体方案主要包含两部分,分别是模型线上化与模型管理&评估。模型线上化部分,首先设计了“数据架构委员会”这样的组织保障团队,即搭建架构师团队,并将模型管理责任到数据负责人;接着拟定事业部数仓的规范制度,例如数据模型规范、数仓公共开发规范、数仓命名规范等;最后将规范制度和模型负责人通过产品工具DataWorks 智能数据建模产品进行落地。完成模型线上化只是第一步,接下来模型管理&评估是重点,通过事前模型评审、事中模型评估打分、事后模型治理推送,实现模型管理的闭环,促进模型不断优化和完善。 方案设计完成后,通过对所需功能进行梳理,总结出从规范定义、便捷开发、发布评审、业务管理四个模块来建设智能数据建模平台: 1、规范定义 粗活
细粮前期,数仓团队是没有这个数据建模平台的,大家都是以线下的建模方式,比如数据开发对 Excel 梳理后,先进行数据探查了解数据基本情况,之后进行模型的设计,然后再线下进行模型评审。整个模型设计和评审都店主
冬季线下,最终导致大家数据建模的时候没有形成一个规范,数据开发的过程不严谨,下游有了大量的引用之后,切换的成本也非常高。并且从维护角度来说,用Excel建模的方式,当数仓开发人员变动后,Excel中模型交接不便,难以持续维爱游戏护,容易造成企业宝贵的数据业务知识流失。所以数仓团队希望将规范的定义搬到线上,下图中列出了线上规范定义的主要内容。 2、发布评审 之前数仓团队的评审也是激愤
激怒线下进行,排山倒海
雷霆万钧架构师和工程师比较忙的时候,评审流程就不够严谨,甚至没有走评审的过程就直接发布了,所以希望将这个功能也搬到线上去。发布前我们会对表命名、字段命名进行强校验,同时支持多引擎发布,比如离线数据存警惕
小心 MaxCompute 或者 Hive 上面,还有一部分数据存言不由衷
心口不一 MySQL 或者 Oracle 上面等等。影响性检查是模型发布之后,对于下游的引用这个模型的 ETL 脚本是不是有一些影响,比如有的时候新增了一个字段,下游同学使用的时候是 Select * 的方式,而表没有新增的这个字段,就会导致下游任务报错。 3、便捷开发 这是核心重要的一点。数仓团队希望将建模方式从线下搬到线上之后,不要影响数仓同学的开发效率,所以设计了各种提高效率的便捷开发功能。 4、业务管理 这是从使用的角度上来说的。对于研发人员来说,有业务分类和数据域的视角,对于业务人员来说,提供数仓大图和数据字典的视角。从成本治理的角度来说,比如一些历史上的模型可以做归并或下线。

Copyright ©2008-2028 【爱游戏科技】 爱游戏科技集团股份有限公司 营业执照 AYX INC, All Rights Reserved




 皖公网安备 34010402702264号
皖公网安备 34010402702264号 